Omnilect, a tool for crowdsourcing linguistic atlases
In between jobs, I did a 9-week web-development bootcamp in Lisbon. The middle three weeks taught backends and API building, and capped off with a pair project. My project partner and I combined our fondness for languages by creating Omnilect, a linguistic atlas website.
Linguistic Atlases!
A linguistic atlas is a collection of maps that document the ways in which language can vary. The maps can document very big differences—like the word for 'one hundred' across Europe—or they can document minor differences—like the second vowel in the Catalan word for "face". Viewed as a whole, this collection of maps can reveal fascinating stories about the way languages grow, evolve, mutate, and commingle.
Making a linguistic atlas is a monumental undertaking, and doing one rigorously is borderline Sisyphean. But with Omnilect, it should at least be easy to get started!
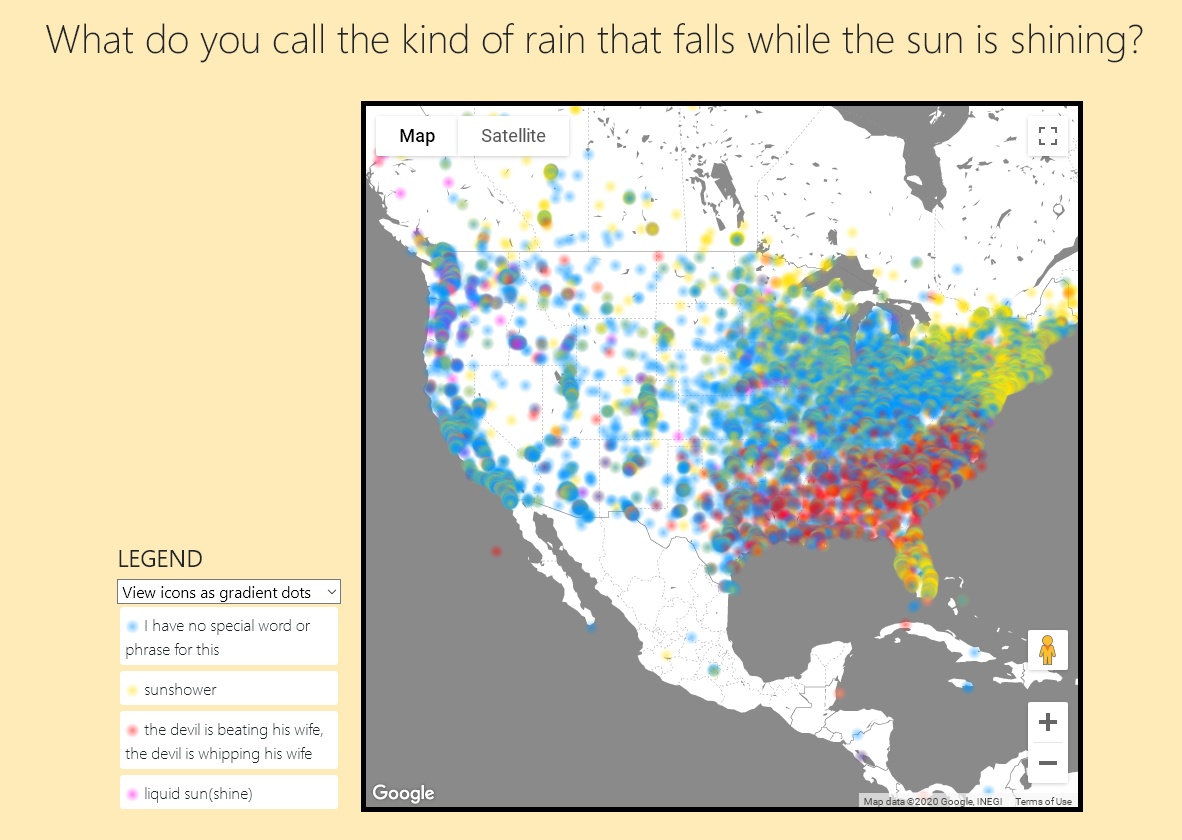
Omnilect in theory and in practice
I want Omnilect to be two things, really. One: a super-broad linguistic atlas that anyone can contribute to. Two: an easy template from which trained linguists can build their own linguistic atlases. At the moment, it's not really either of these things, but it's definitely closer to item One.
Not surprisingly, the two key features of the site are (a) a convenient way to collect data, and (b) a convenient way to display data. Neither one is trivial. The former requires us to engage users and track their responses without storing personal user data; the latter requires a data-visualization scheme that will faithfully represent the data collected without looking ugly. But without a real use case, I think Omnilect will stay in its current condition for a while.